Attention
$$ A_{ij} = \frac{\exp(S_{ij})}{\sum_j \exp(S_{ij})}, \quad S_{ij} = \textcolor{blue}{\langle \bm{q}_i, \bm{k}_j \rangle} / \sqrt{d}, \\ \bm{q} = W_Q\bm{x}, \bm{k} = W_K\bm{x} \in \mathbb{R}^d, \quad i, j = 0, 1, \ldots, L-1. $$- 特殊类型的 Attention 的 Graph 形态:
Note: Attention 实际上定义了序列中各个位置的 Connection 强度
Over-Squashing in Graph Neural Networks
- 广泛的连接导致过于狭窄的信息传递:
- 感受野随着层数增加指数增加 $\rightarrow$ 难以捕获 Long-range 的信息
Note: 需要说明的是, 从这篇文章出发, Causal Attention 的 Bottleneck 并不严重
Over-Squashing in Graph Neural Networks
- 实验(必须依赖 $\textcolor{blue}{k}$-阶邻居预测标签):
- Attention (GAT) 以及门控 (GGNN) 有助于缓解 over-squashing
Note: 随着层数的增加, 由于 over-squashing 的存在, GNN 越来越难利用到 long-range 的’邻居’信息
‘Over-Squashing’ in Large Language Models
- Over-Squashing: Early tokens 有更多的影响
- Representational Collapse: 随着序列长度增加, 表示趋近${}^{\tiny [1]}$
- Attention Sink: LLMs 总是倾向于给予
token 很高的权重${}^{\tiny [2,3]}$
Note: 在 GNN 中, over-squashing 指的是膨胀的感受野导致每个邻居的贡献很有限; 而在 LLM 中, over-squashing 指的是 early tokens 会产生更多的影响. 虽然二者可能都会导致类似 representational collpase 的现象, 但是严格来说不能混为一谈. 实际上, LLM 中是否存在所谓的 over-squashing 问题也是个未知数, 因为 Causal Attention 实际上已经是 Graph 领域里一个推荐的方案了.
‘Over-Squashing’ in Large Language Models
Theorem B.3 (Representational Collapse) Let $X = [\bm{x}_0, \ldots, \textcolor{blue}{\bm{x}_{n-1}}] \in \mathbb{R}^{n \times d}$ and $X^* = [\bm{x}_0, \ldots, \textcolor{blue}{\bm{x}_{n-1}, \bm{x}_{n-1}}] \in \mathbb{R}^{(n + 1) \times d}$ be two sequences for a final repeated token $\bm{x}_{n-1}$, with
- All token representations bounded ($S_{i, j}$ is bounded) ;
- Positional encodings decay with distance to 0 ($S_{n-1, j} \approx S_{n, j}^*$ as $j \rightarrow 0$) .
Then, for large enough $n \in \mathbb{N}_+$, we have that the representations are under any $\epsilon$:
$$ \|\bm{x}_{n-1}^{(L)} - {\bm{x}_{n}^{*}}^{(L)} \|_1 \le \epsilon. $$Note: 证明的关键是保证 Attention 能够尽可能一致, 因而加权和之后的向量表示也一致. 第一个条件主要是保证自己和自己的 score 算出来不会无限大, 否则就一定有区别, 另一个条件主要是保证 Attention 是渐进一致的.
Copying
- First-token copying:
- Input: ‘$\textcolor{red}{0}111\ldots 111$’; Target: ‘$0$’
- Last-token copying:
- Input: ‘$111\ldots 111\textcolor{red}{0}$’; Target: ‘$0$’
- 逐步增加 ‘1’ 以增加序列长度:
- (B) Hint: It’s not necessarily a 1, check carefully ;
- (C) ‘$0111 \ldots 11$’ 替换为 ‘$0111 \ldots 11 \: 0111 \ldots 11 \: \ldots$
Note: Copying 的例子有趣在于: First-token copying 比起 Last-token copying 反而更容易. 通过 ‘over-squashing’ 解释就是, first-token copying 能够产生更多的影响.
Counting
$\textcircled{\small 1}$ 求和: $1 + \cdots + 1$;
$\textcircled{\small 2}$ 计数: 统计一串均为 1 的序列中有多少个 1;
$\textcircled{\small 3}$ 计数: 统计一串 0/1 序列中有多少个 1 (1 出现的概率为 70%);
$\textcircled{\small 4}$ 单词计数: 统计一串序列中某个词出现的次数.
- 三种策略:
- 直接输出结果 (No CoT);
- 思维链 (CoT Zero-Shot);
- 例子 + 思维链 (CoT Few-Shot).
Counting
-
难度: $\textcircled{\small 3} < \textcircled{\small 1} \approx \textcircled{\small 4} < \textcircled{\small 2}$
-
策略: No CoT $\approx$ CoT Zero-Shot $>$ CoT Few-Shot
Note: 这个例子主要是说明’间隔’符号对于 Counting 的帮助.
Positional Encoding
$$ A_{ij} = \frac{\exp(S_{ij})}{\sum_j \exp(S_{ij})}, \quad S_{ij} = \textcolor{blue}{\langle \bm{q}_i, \bm{k}_j \rangle} / \sqrt{d}. $$- RoPE (Rotary Positional Encoding)
- $\theta_i = b^{-2i / d}$ 表示基本的旋转单位, $b$ase 越大, 旋转的角度越小.
Note: 位置编码有可能可以缓解 Connection Bottleneck
Positional Encoding
- 位置编码: 维度靠前 $\rightarrow$ 高频区域; 维度靠后 $\rightarrow$ 低频区域
Note: 注意, 这里的高低频针对的是位置编码而不是输入信号 (query or key)
Positional Encoding
- RoPE 的距离衰减:
-
Left: RoPE 下的 Attention 的某个上界随着 $|j - i|$ 增加而衰减
-
Right: 高斯噪声下, 真实的 Attention 并无衰减现象
Positional Encoding
- 个人的测试:
- 即使 relative distance 增加到 100,000 依然没有距离衰减的现象
Note: 横坐标是相对距离
RoPE 的高频
- 猜想: 过大的旋转角度会导致对应维度所得结果趋于噪声
- Exception: First and Last Layers
Note: 这是一个隐式的例子: 作者将维度两两分组, 假设模长越大越偏向于语义信息. 在绝大部分 layers 中高频部分仅被分配了较小的模长, 例外是初始的和最后的一些层.
RoPE 的高频
- 猜想: 高频有利于特殊 Attention 形态的构建
$\textcircled{\small 1}$ Last Layers: Diagonal attention $\textcircled{\small 2}$ First Layers: Previous-token attention
Note: 最开始的层倾向于 previous-token attention, 而最后的几层则倾向于 diagonal attention. Previous-token attention, 即 attention sink 现象在下面的文献有所讨论.
RoPE 的高频
❓ 不施加位置编码, 是否依然能形成特殊的 Attention 形态
-
结论:
- 在不施加任何位置编码的前提下: 对于重复的序列, 必不存在 ‘Diagnoal’ 或 ‘Previous-token’ 类型 Attention
- 在施加 RoPE 前提下: 对于任意序列, 模型总能通过学习特定模长来形成 ‘Diagnoal’ 或 ‘Previous-token’ 类型 Attention
-
总而言之, 位置编码赋予了模型关注特定区域的能力, 有可能缓解 connection bottleneck
RoPE 的低频
❓ $\theta_i = b^{-2i / d} \xrightarrow{\textcolor{blue}{b \uparrow}} \text{long-context ability} \uparrow$
1. Long-term decay of upper bound of attention score
- Long-term Decay of the Ability to Attend More to Similar Tokens than Random Tokens
RoPE 的低频
-
$\bm{q}, \bm{k}$ 独立同分布, $\mathbb{E}[\bm{\epsilon}] = 0$.
-
希望 $\bm{q}, \bm{q} + \bm{\epsilon}$ 的 attention 严格大于 $\bm{q}, \bm{k}$ 的需要满足:
- 理论上 base $b$ 的 lower bound:
Connection Bottleneck
Counting (314 ‘1’)
| Length | ‘1…’ | ‘1,1…’ | ‘1,1,1,1,1;1,…’ | |
|---|---|---|---|---|
| Mistral Medium | 32k | 500 | 500 | 500 |
| Deepseek-R1 | 64K | 264 | $\textcircled{\small 1}$ | 299 |
| GPT-4o | 128k | 300 | 300 | 340 |
| Llama3.3-70b | 130K | ‘The string 1111…’ | 150 | ‘…The string is 1,1,1,1,1;1,…’ |
| o4-mini | 200k | 232 | 270 | 319 |
$\textcircled{\small 1}$ Given that, and since the sequence is uniform, the count is the number of '1's, which is the total numbers in the sequence. Given that, and since counting manually is not feasible, the answer is that all numbers are '1's, hence the count is equal to the number of numbers in the sequence. But since the exact count isn't provided, perhaps the answer is to recognize that every number is '1'.
Counting
Case I: “y,x,y,y,x,y,y,x,y,x,y,y,y,y,x,y,y,y,x”
Case II: “yxyyxyyxyxyyyyxyyyx” (ACC = 0.16%)
- ‘间隔符’ 用处很大, base $b$ 似乎没有明显的规律.
💡 Connection Bottleneck
- 更好的位置编码? No!
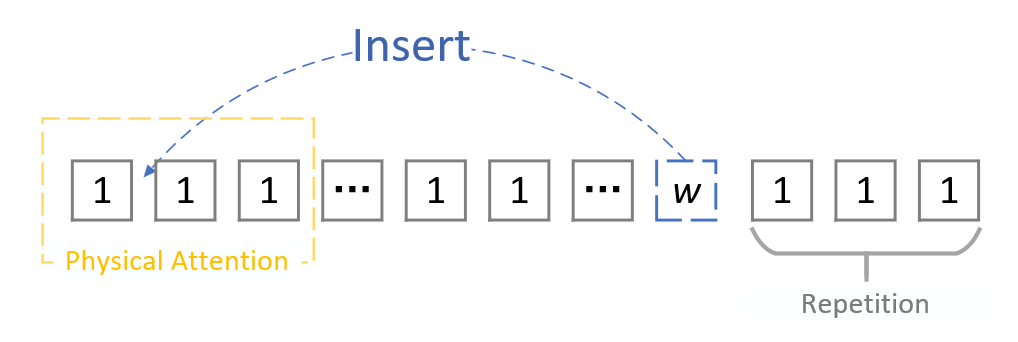
- 物理层面的 Attention?
Note: 个人认为, 纯粹的位置编码是应付不了需要极端注意力的情况的. 我们需要物理层面的干预, 来帮助 LLM 减少无关信息.