Background
- 可能的一些解决方案:
- MoE, LoRA; ZeRO, FSDP;
- Network Quantization; Lightweight Optimizers
Background
⚙️ Optimizer States (2x model size):
$$ m_{t+1} \leftarrow \beta_1 \cdot m_t + (1 - \beta_1) \cdot g, \\ v_{t+1} \leftarrow \beta_2 \cdot v_t + (1 - \beta_2) \cdot g^2 $$- Lightweight Optimizers:
- 重新设计: Lion, Muon …
- 状态共享: Adafactor, SM3, Adam-Mini …
- 降维/稀疏化: GaLore, MicroAdam
- 低精度: 1-bit SGD/Adam, 16/8/4-bit Optimizers, Q-GaLore, 8-bit Muon
Why Low-Bit Optimizers?
-
泛化性: ✅无需额外调参 ✅适用任意场景
-
灵活性: ✅非环境依赖
-
成功的工程实践: DeepSeek-v3 训练框架 ($g \overset{\text{BF16}}{\rightarrow} m,v \overset{\text{FP32}}{\rightarrow} \theta$)
Quantization and Dequantization
-
Quantization:
$$ q = Q(x) := \mathop{\text{argmin}} \limits_{k=0}^{2^b - 1} \big|\frac{x}{\textcolor{red}{\Delta}} - \textcolor{red}{y_k} \big|. $$
- Dequantization:
Stateful Optimizers in Ultra-LOw Bits
Challenges in Ultra-Low-Bit Cases
-
表示精度: 42 亿 (32-bit) vs. 8 (3-bit) vs. 4 (2-bit)
-
量化范围: 如何将尽可能多的元素一起量化?
-
一阶/二阶动量:
- (Signed) 一阶动量 ($m$): 决定参数更新方向
- (Unsigned) 一阶动量 ($m$): 决定参数更新步长
Quantization for Unsigned EMA Update
- Signal Swamping (large-to-small number addition)
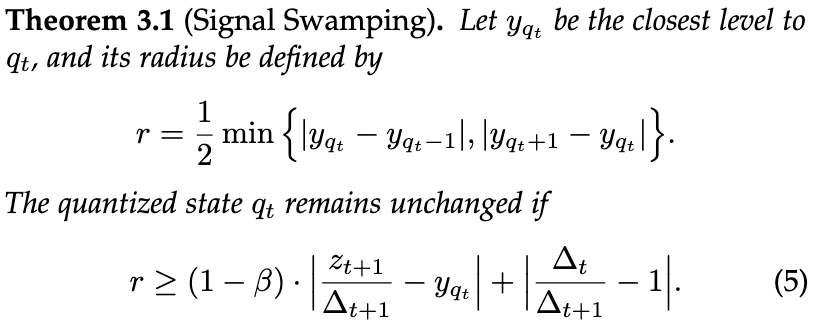
Signal Swamping
💡 总结
Case Study
-
一定条件下:
- Linear 下全部不更新
- DE 下部分更新
-
实际上 $\beta \ge 0.9$ 为相当常见的 setting
Case Study
-
随机信号:
- $X \in \mathbb{R}^{1000}$
- $Z \sim \mathcal{U}[0, 1]$
-
Relaxed 条件:
X Fixed $\Delta$
X $z \le \Delta$
- 理论收敛至: $0.5$
Solution (1/2): Stochastic Rounding
-
假设 $y_{k-1} \le x / \Delta \le y_k$:
$$ Q_{sr}(x) := \left \{ \begin{array}{ll} k-1 & w.p. \quad \frac{y_k - x / \Delta}{ y_k - y_{k-1}}, \\ k & w.p. \quad \frac{x / \Delta - y_{k-1}}{ y_k - y_{k-1}}. \end{array} \right . $$ -
High variance:
(Solution 2/2) Logarithmic Quantization
- 3-bit quantization levels (Linear vs. Dynamic Exponent vs. Ours):
Logarithmic Quantization
- 2-bit quantization illustration
Logarithmic Quantization
✅ Easy to implement
✅ State decay alignment
Quantization for Signed EMA Update
😄 No Signal Swamping
😞 额外的符号表示 (1 bit)
😞 直接决定更新方向 (误差敏感)
💡 总结:
Quantization Errors $\Rightarrow$ Gradient Variance
$\rightarrow$ Bits $\downarrow$ or $\beta \uparrow$
$\rightarrow$ Quantization errors $\uparrow$
$\rightarrow$ gradient variance $\uparrow$
$\rightarrow$ worse convergence
Momentum Adjustment
- 方差控制: 选择 $\beta'$ 满足:
- 查表: (灰色区域代表了经验可行的参数推荐)
Experiments
😒 传统方法: $\underset{\text{Training from scratch}}{\xrightarrow{\text{Ultra-Low-Bit}}}$ degeneration/collapse
😊 SOLO: Robust to bits/tasks/models
Experiments (Giant Models)
Loss
- 损失正常收敛
Quantile $x_p$
- 基本上 $p \in [0.05, 0.3]$ 都有不错的性能
Beta, Block size
- Lower-bit SOLO needs a smaller $\beta$
State Changes
Generalizability of SOLO
- AdaBelief
- Larger-scale models: