Markovian Pre-Trained Transformer for Next-Item Recommendation
Content
研究背景
-
(Recommendation Foundation Model) 在 pre-training & fine-tuning 的大时代背景下, 大多数推荐模型依旧沿用单场景从头训练的范式, 因此难以享受到预训练模型带来的数据共享和泛化优势. 诚然, 已经有 UnisRec 等工作尝试用多场景推荐数据训练预训练模型, 但在效果和效率上仍然存在明显限制.
-
(Data Simulation) 在其他领域也会遇到高质量数据难以获取的困境, PFN 等方法开始尝试在合成数据上进行预训练, 得到预训练模型, 然后通过 fine-tuning 甚至 zero-shot 推广到真实场景. 那么, 推荐场景是否也存在类似的机会?
-
(符号说明)
- 商品 (item): $v \in \mathcal{V}$;
- 状态 (state): $s \in \mathcal{S}$;
- 状态转移概率矩阵: $\mathbf{P} \in \mathbb{R}^{|\mathcal{S}| \times |\mathcal{S}|}$;
- 狄利克雷分布: $\text{Dir}(\bm{\alpha})$.
核心思想
序列推荐的 “马尔科夫性”
-
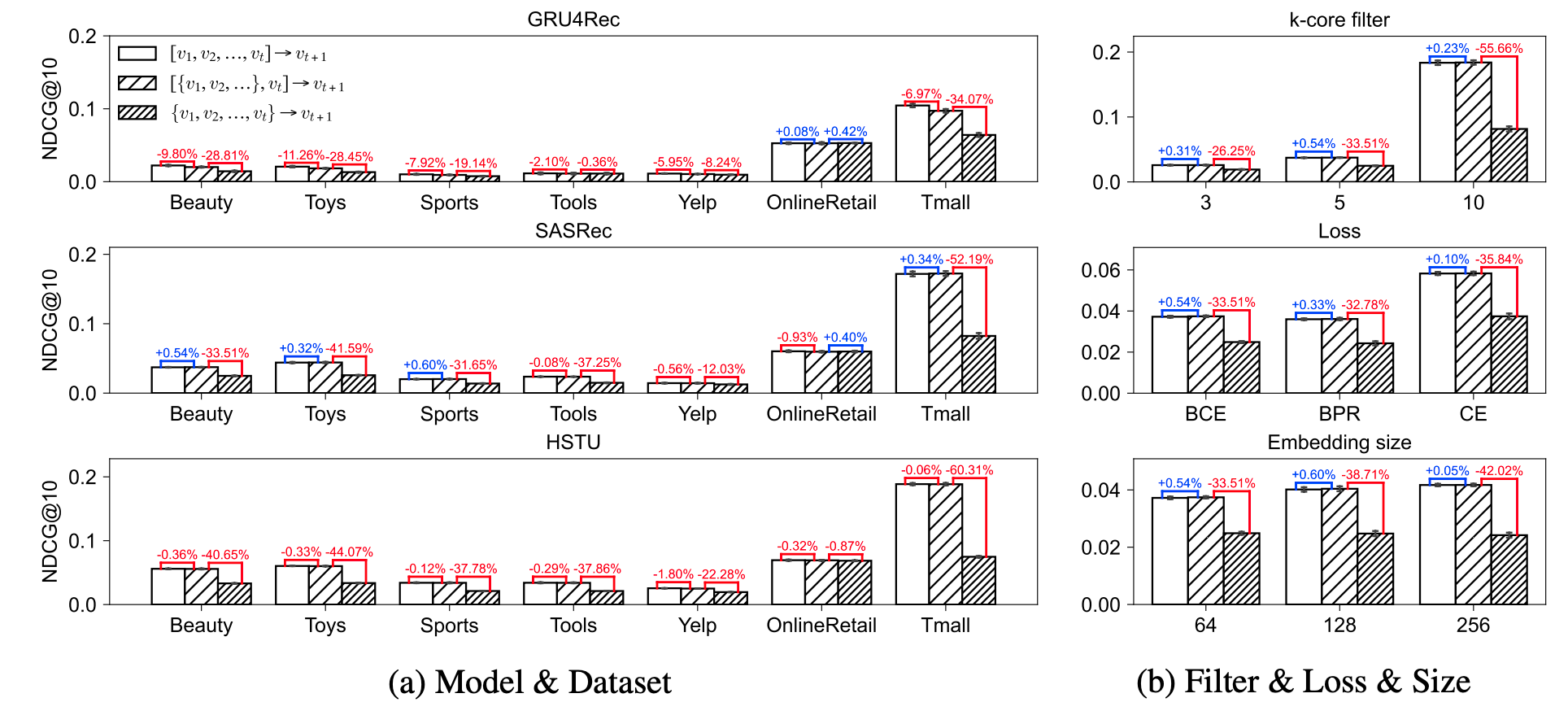
(序列推荐的惯性思维) 序列推荐模型的结构是逐步复杂化的, 从 Caser、GRU4Rec、SASRec 到现如今的 HSTU, 很自然的想法是: 越复杂的模型内部应该进行了更复杂的“推理”, 从而获得更好的推荐效果. 在上图中, 作者在不同数据集和数据划分标准下, 对不同模型测试了如下三种方案:
- ① 顺序排列: $\mathbb{P}(v_{t+1} | v_t, v_{t-1}, \ldots, v_1; \Theta)$;
- ② 部分乱序: $\mathbb{P}(v_{t+1} | v_t, \{v_{t-1}, \ldots, v_1\}; \Theta)$;
- ③ 完全打乱: $\mathbb{P}(v_{t+1} | \{v_1, v_2, \ldots, v_t\}; \Theta)$.
如果序列推荐确实高度依赖完整的时序推理, 那么应该有 ① 明显优于 ② 和 ③. 然而, 实际情况更接近 $① \approx ② \gg ③$.
-
(序列推荐的马尔科夫特性) 因此, 总结来说, 序列推荐并没有因为模型变得更强、更复杂就自然转向更复杂的推理模式. 表现优异的模型, 尤其是 Transformer 类模型, 通常遵循两点: (I) 需要特别关注用户最近的交互 $v_t$; (II) 用户序列 $[v_1, v_2, \ldots, v_t]$ 中, $\{v_1, v_2, \ldots, v_{t-1}\}$ 提供了一种非序列化的上下文信息, 用于确定用户的整体偏好. 因此, 一个好的序列模型应该近似满足:
$$ \tag{1} \mathbb{P}(v_{t+1} | v_t, v_{t-1}, \ldots, v_1; \Theta) \approx \mathbb{P}(v_{t+1} | v_t, \underbrace{\{v_1, v_2, \ldots\}}_{\text{non-sequential context}}; \Theta). $$这实际上是一种特殊意义下的马尔科夫性.
Markovian Pre-Trained Transformer
-
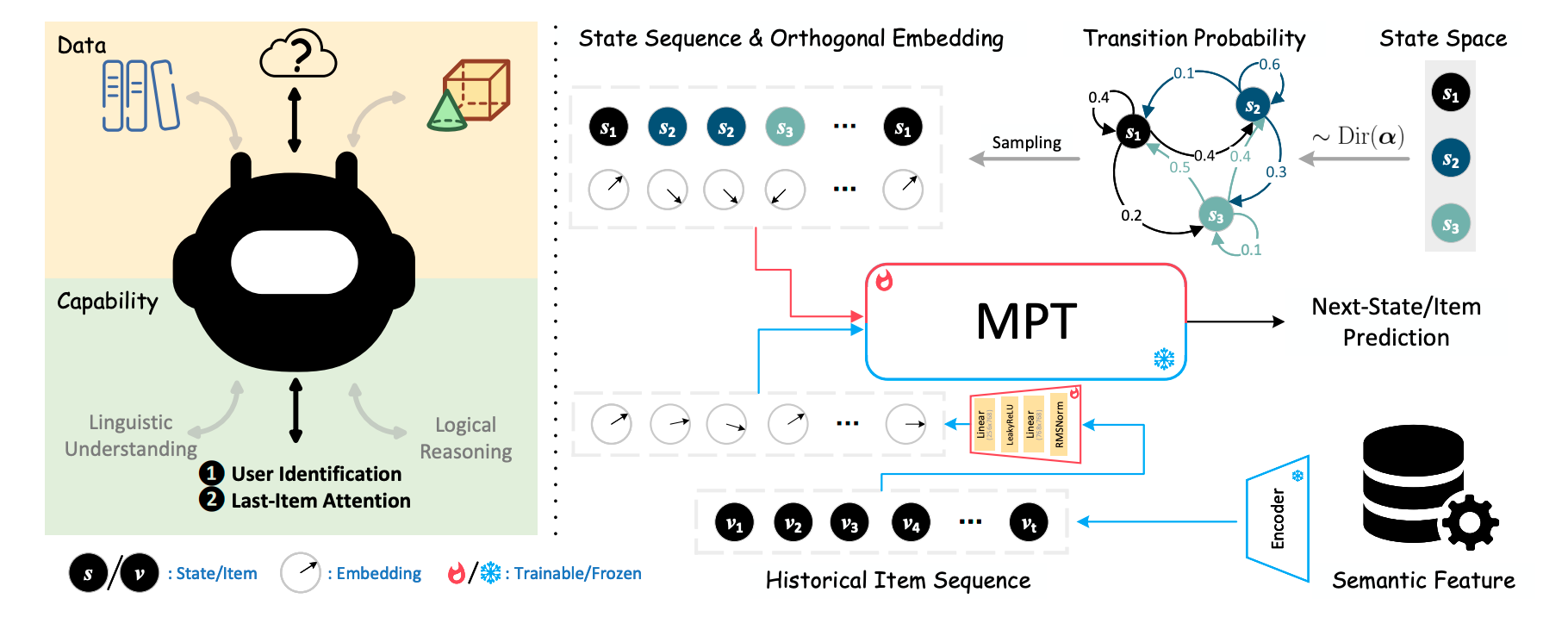
(Markovian Pre-Training) 作者认为, 推荐模型所需要的能力和“根据马尔科夫链轨迹预测下一个状态”的能力是一致的. 给定马尔科夫链的采样轨迹 $[s_1, s_2, \ldots, s_t]$, 想要预测下一个最可能的状态 $s_{t+1}$ 大致需要两步:
- 转移概率矩阵估计 (对应用户偏好估计): 根据状态转移频率估计状态转移概率矩阵;
- 最大后验估计 (对应关注最新交互 $v_t$): 根据状态转移概率, 选择从 $s_t$ 出发最可能到达的状态 $s_{t+1} \in \mathcal{S}$.
因此, MPT 在预训练阶段以 Next-State Prediction 为目标:
$$ \tag{2} \mathcal{L}_{\text{NSP}}(\Theta) = \mathbb{E}_{\mathbb{P} \sim \text{Dir}(\bm{\alpha})} \mathbb{E}_{\{s_t\}_{t=2}^T \sim \mathbf{P} | s_1} \left\{ -\sum_{t=1}^{T-1} \log \mathbb{P}(s_{t+1} | s_t, \ldots, s_1; \Theta) \right\}. $$其中 $\mathbf{P}$ 是从 Dirichlet 先验中采样的转移概率矩阵.
-
(Recommendation Fine-tuning) 这一步主要是为了对齐推荐 item embedding 空间和预训练空间. 论文中主要冻结 MPT 主体参数, 只微调输入端的 adaptor:
$$ \tag{3} \mathcal{L}_{\text{NIP}}(\theta) = -\sum_{t=1}^{T-1} \log \mathbb{P}(v_{t+1} | v_t, \ldots, v_1; \Theta, \theta). $$
关键洞察
-
(Adaptor > LoRA) 虽然 LoRA 的适配能力更强, 但作者发现在很多场景下, LoRA 微调反而不如只训练输入端 adaptor. 一个合理的解释是: 推荐数据中的噪声和分布差异可能会破坏预训练模型已经获得的能力. 当然, 这并不意味着 LoRA 一定不适合推荐, 更准确地说是 MPT 在多数实验中更偏好轻量的输入空间对齐.
-
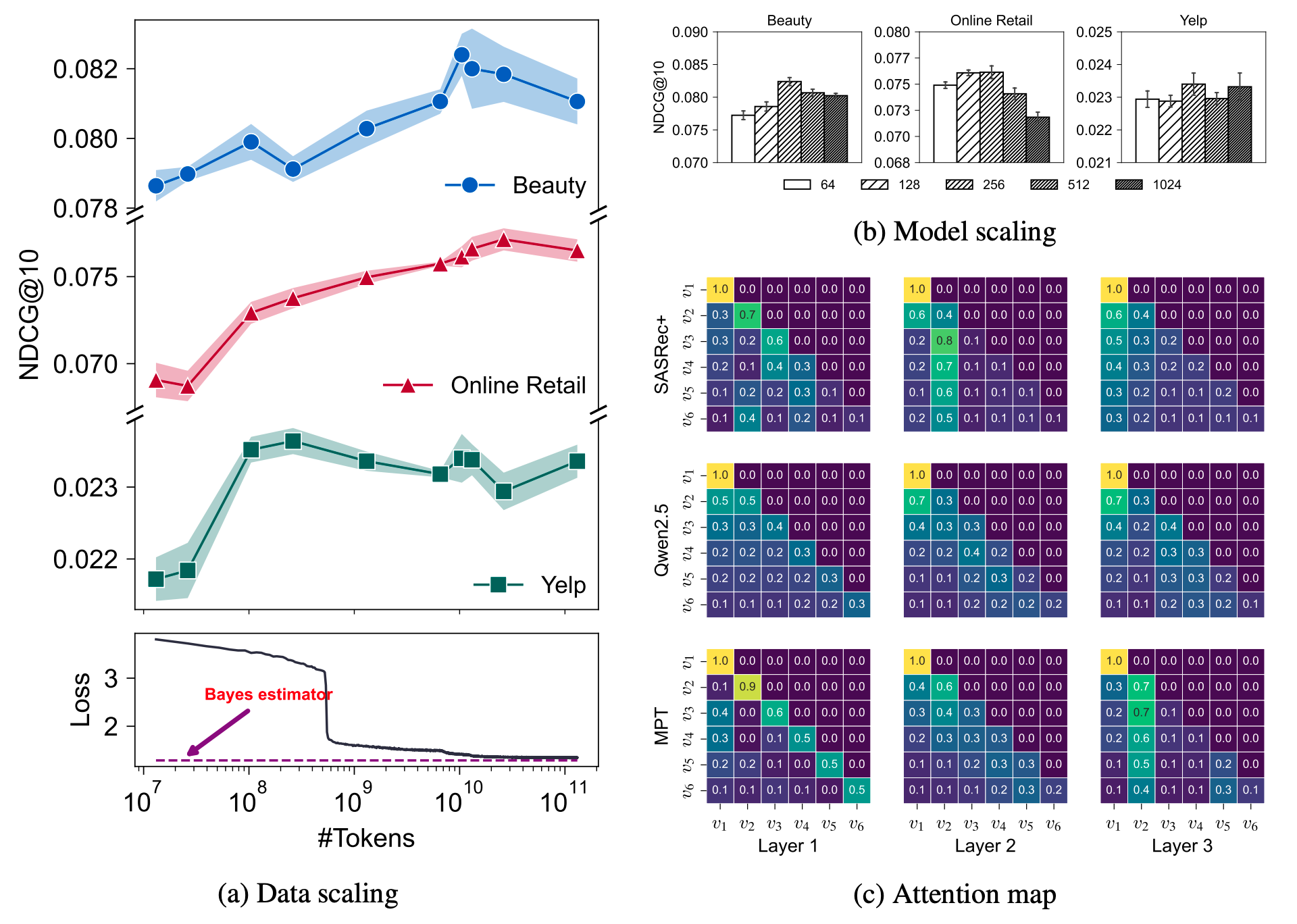
(Scaling Law) 有趣的是, MPT 也展现出了 Scaling Law. 随着预训练数据增加, 下游推荐效果逐步提升, 直到 10B 左右 tokens 后趋于饱和. 作者认为, 这个饱和主要来自 Markovian Pre-training 本身存在理论上界 (见附录).
继往开来
-
如何训练出一个推荐预训练模型一直是推荐社区的痛点. MPT 从能力角度出发, 用合成数据激发推荐模型所需能力, 这个范式本身很有意义.
-
这篇文章最有意思的地方不在于又提出了一个 Transformer, 而在于它把序列推荐中的“最近交互 + 非序列上下文”这个现象明确抽象成了 Markovian pre-training. 这为推荐 foundation model 提供了一个更干净、也更容易分析的起点.
附录
MPT 的理论界限
-
马尔科夫链的采样过程可以看成是 $|\mathcal{S}|$ 个 categorical distributions $\{\text{Cat}(|\mathcal{S}|; \mathbf{p}_i)\}_{i=1}^{|\mathcal{S}|}$, 其中 $\mathbf{p}_i \in [0, 1]^{|\mathcal{S}|}$ 表示状态 $s_i$ 转移到其他状态的概率, 在本文中采样自 Dirichlet 先验.
-
由于 Dirichlet 先验和多项式分布的共轭关系, 状态转移的后验分布为:
$$ \mathbf{p}_i | [s_1, s_2, \ldots, s_T] \sim \text{Dir}(c_{i,1} + \alpha_1, c_{i,2} + \alpha_2, \ldots, c_{i, |\mathcal{S}|} + \alpha_{|\mathcal{S}|}), $$其中 $c_{i,j}$ 表示整个轨迹中从状态 $i$ 转移到状态 $j$ 的次数统计. 因此, 对于任意一条轨迹, Bayes-optimal estimator 为:
$$ \hat{p}_{i,j} = \mathbb{E}[p_{i,j} | [s_1, s_2, \ldots, s_T]] = \frac{c_{i,j} + \alpha_j}{\sum_{k=1}^{|\mathcal{S}|}(c_{i,k} + \alpha_k)}. $$MPT 预训练只能收敛到这个估计结果附近, 因此不同于一般的 Scaling Law, MPT 存在一个明确的理论界限.