R3-VAE: Reference Vector-Guided Rating Residual Quantization VAE for Generative Recommendation
Content
研究背景
-
(Generative Recommendation) 在 TIGER, OneRec 这类生成式推荐系统中, item 不再直接以原始 ID 进入模型, 而是先被 tokenizer 转换成一组 Semantic IDs (SIDs), 然后由生成模型自回归地产生目标 item 的 SID. 因此, tokenizer 的质量会直接决定召回空间、冷启动能力和生成式推荐模型的上限.
-
(SID Tokenizer) 当前主流方案大体来自 RQ-VAE 或 Residual KMeans. 它们都遵循 “coarse-to-fine” 的残差量化思路, 即逐层用 codeword 解释当前残差, 最后把每一层选中的 code 拼成 SID. 这套范式较为流行, 但存在两个核心问题:
- 训练不稳定: RQ-VAE 依赖 STE 传递梯度, 容易出现 codebook collapse.
- 评估不高效: SID 质量通常要通过完整的 GR 训练和 A/B test 验证, tokenizer 本身缺少可快速迭代的代理指标.
核心思想
Reference Vector Projection
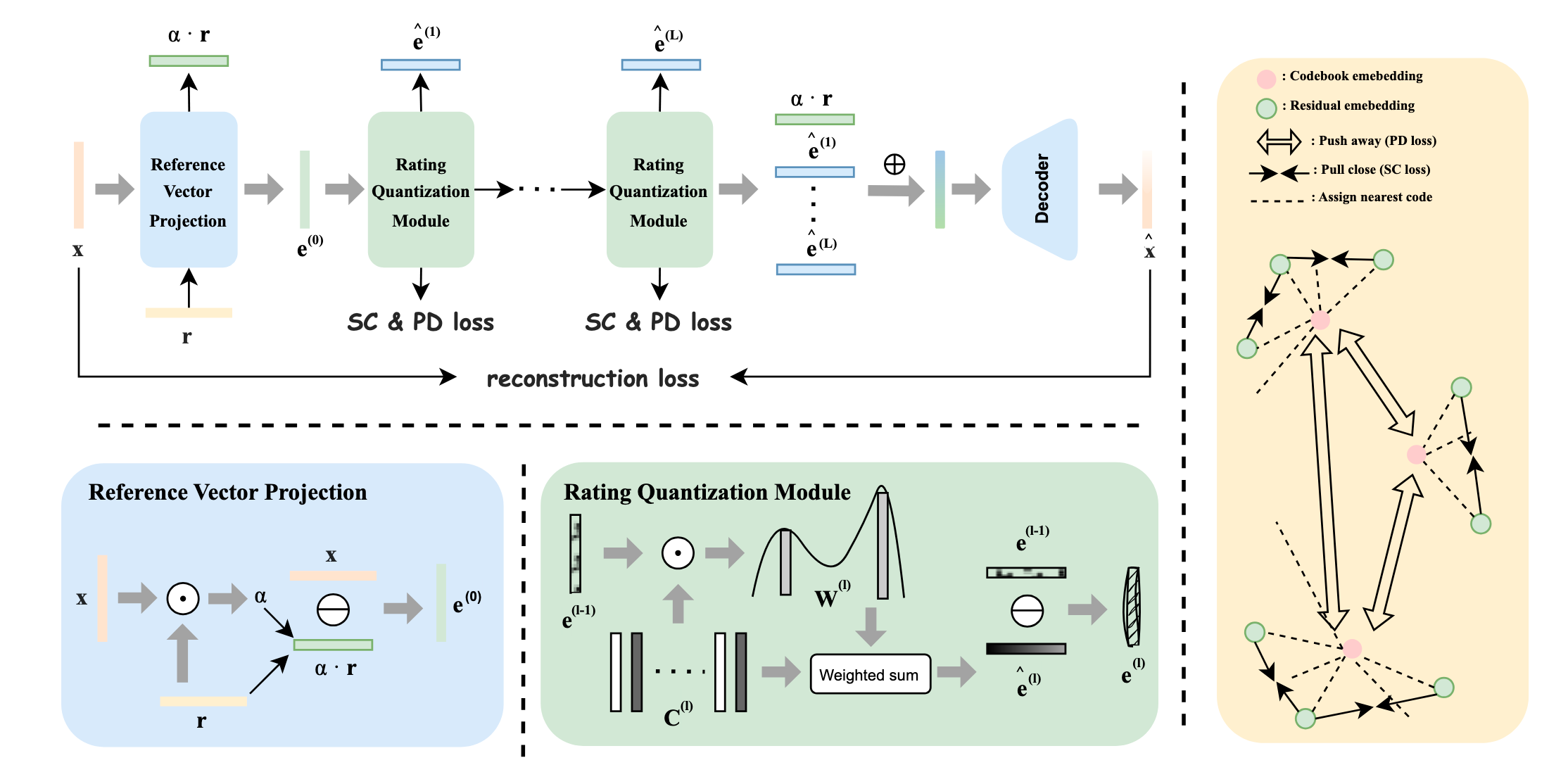
-
R3-VAE 首先引入一个可学习的 reference vector $\mathbf{r} \in \mathbb{R}^d$, 将其视为推荐数据中的语义锚点. 对于 item embedding $\mathbf{x}$, 先计算其在 $\mathbf{r}$ 上的投影:
$$ \alpha = \frac{\mathbf{x} \cdot \mathbf{r}}{\|\mathbf{r}\|_2^2}, $$再得到初始残差 (从分量角度上来说, $\mathbf{e}^{(0)}$ 为 $\mathbf{x}$ 在 $\mathbf{r}$ 上的垂直分量):
$$ \mathbf{e}^{(0)} = \mathbf{x} - \alpha \cdot \mathbf{r}. $$ -
直觉上, 这一步是把 embedding 中更接近全局语义中心的部分先剥离掉, 让后续残差量化面对的是更有区分度的部分. 这和普通 RQ-VAE 直接从 $\mathbf{x}$ 开始量化不同, 它试图减少初始化带来的随机性.
Rating Quantization
-
传统 RQ-VAE 通过 hard nearest neighbor 选 codeword, 再用 STE 近似梯度. R3-VAE 则把每个 residual 和 codeword 的匹配关系改成一个 soft rating (抱歉, 我对其可靠性存疑, 因为其实和 Gumbel-Softmax 有一些像,个人在欧式距离上尝试 Gumbel-Softmax 并没有取得理想的效果, 或许 cosine 相似度是关键?).
-
对第 $l$ 层 codebook $\mathcal{C}^{(l)} = \{\mathbf{c}^{(l)}_k\}_{k=1}^K$, 先用 normalized dot product 计算残差 $\mathbf{e}^{(l-1)}$ 与 codeword 的相似度:
$$ s^{(l)}_k = \frac{\mathbf{e}^{(l-1)} \cdot \mathbf{c}^{(l)}_k} {\|\mathbf{e}^{(l-1)}\|_2 \times \|\mathbf{c}^{(l)}_k\|_2}. $$然后通过 softmax 得到权重:
$$ w^{(l)}_k = \frac{\exp(s^{(l)}_k)} {\sum_{k'=1}^K \exp(s^{(l)}_{k'})}. $$ -
训练时的量化表示不是某一个 hard codeword, 而是加权和:
$$ \hat{\mathbf{e}}^{(l)} = \sum_{k=1}^K w^{(l)}_k \cdot \mathbf{c}^{(l)}_k, \quad \mathbf{e}^{(l)} = \mathbf{e}^{(l-1)} - \hat{\mathbf{e}}^{(l)}. $$这样 reconstruction loss 的梯度可以更平滑地传到 codebook 和前面的网络, 不需要完全依赖 STE. 生成 SID 时, 再取每一层权重最大的 codeword index 拼接成离散 ID.
SID Quality Metrics
-
R3-VAE 还提出了两个 SID 质量指标 (启发自 LETTER), 并把它们作为正则项加入训练:
- Semantic Cohesion (SC): 同一个 SID cluster 内的 item embedding 应该足够一致. SC 越高, 表示同一组 SID 捕捉到的语义/偏好越集中.
- Preference Discrimination (PD): 不同 SID cluster 之间应该有足够区分度. 论文中 PD 越低越好, 表示不同 cluster 的偏好模式更容易被区分.
-
这两个指标的意义不只在于解释性. 更关键的是, 它们可以在 tokenizer 训练阶段直接优化和观察, 不必每次都跑完整的生成式推荐训练.
关键洞察
- 作者在常用的公开数据集以及工业场景上均进行了充分实验, 证明了 R3-VAE 方法的有效性, 而且上述提出的 SID quality metrics 也的确和最终的推荐指标存在紧密联系.
继往开来
- 个人认为作者团队提出的生成式推荐目前所存在的问题非常关键, 虽然所提出的方法是否在优化层面解决了"不稳定性"我依然持怀疑态度.